Tracking the global Opus Magnum records
Hey gamers, happy 2023. This year brings with it a new Opus Magnum tournament, and with it a renewed surge of interest in the game itself. In this post, I’ll give a bit of a history lesson on how the game’s leaderboards have evolved. I’ll link to other posts on this blog for further context, but I think this post should be accessible on its own. By the end, I’ll discuss the very recent and highly controversial “pareto manifold split,” words which will make sense by the time we get there. Enjoy!
In-game leaderboards
Since the core principle of Opus Magnum is to optimize, the game includes leaderboards. They come up every time you complete a level, and show your score both on a histogram, and listed against your Steam friends (assuming you have the game via Steam). You get one score for cost, one for cycles, and one for area.

The histograms come from a large steam database containing, for every puzzle:
- A list of the steam user IDs to have a solution for that puzzle
- The user’s lowest cost across all of their solutions
- The user’s lowest cycles across all of their solutions
- The user’s lowest area across all of their solutions
Players can build multiple solutions for any puzzle. As a consequence, it’s difficult (sometimes impossible) to be to the left of the histogram peak at everything simultaneously. The list you are competing against isn’t individual solutions. It’s a combination of the best scores from every solution someone’s made to that puzzle.
Top Percentile
When you beat the main campaign of the game, you unlock the option to view “Top Percentile” in this leaderboard screen. The source data for top percentile is the same database. It displays the cost when looking 1% of the way down the sorted list of users’ best cost, and same for cycles and area.
Why would it be the top percentile and not the actual record? As shown in Visillary Anaesthetic, the top percentile on cycles is 31. But I have 30, and Grimmy has 29. Well, the reason comes from the relative ease of cheating in this game. I’ve blogged before about overlapping parts with each other. There’s also a (now-patched) superglitch where you could start simulation with the output not placed, causing the game to think the puzzle is solved on cycle 1.

Looking at only the top score in the database, it may very well be a cheated score. Thankfully, the top percentile is very unlikely to be cheated, as the number of players is well over 100x the number of shameless cheaters. (Those of us who do still cheat in 2023 mostly have the decency to use Hermit Mode, which disables steam submissions).
We want more!
The in-game leaderboards are fine for casual competition. However, the reality of Opus Magnum is that a skilled player can often build the theoretical minimum cost, cycles, or area solution without too much effort. This is especially true for most of the campaign, which has easier puzzles. There are, of course, notable exceptions (looking at you surrender flare).
If I pick an arbitrary campaign puzzle, I end up seeing a smear of the same score for all my top steam friends.

This spells out the need for secondary metrics. Once you have the minimum cycles (for example), you would want to compare your minimum-cycle solution to other people’s minimum-cycle solutions, and find which one is better.
Early days
In October 2017, before the game even left early access, reddit user Obyekt posted the “cycle count leaderboards“. This leaderboard had only a few of the levels, those deemed “interesting”. It only ranked scores in a single way. Cycles was the primary metric. Ties in cycles were broken by cost, and ties in both were broken by area. Submitters had to include a gif of their solution for it to count, meaning that others immediately had access to the design and could replicate or improve it.
In practice
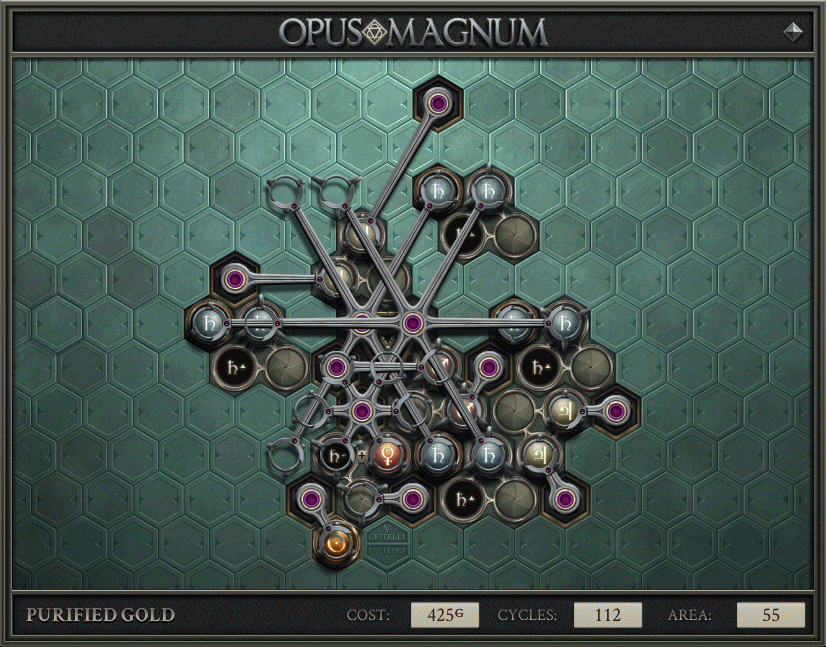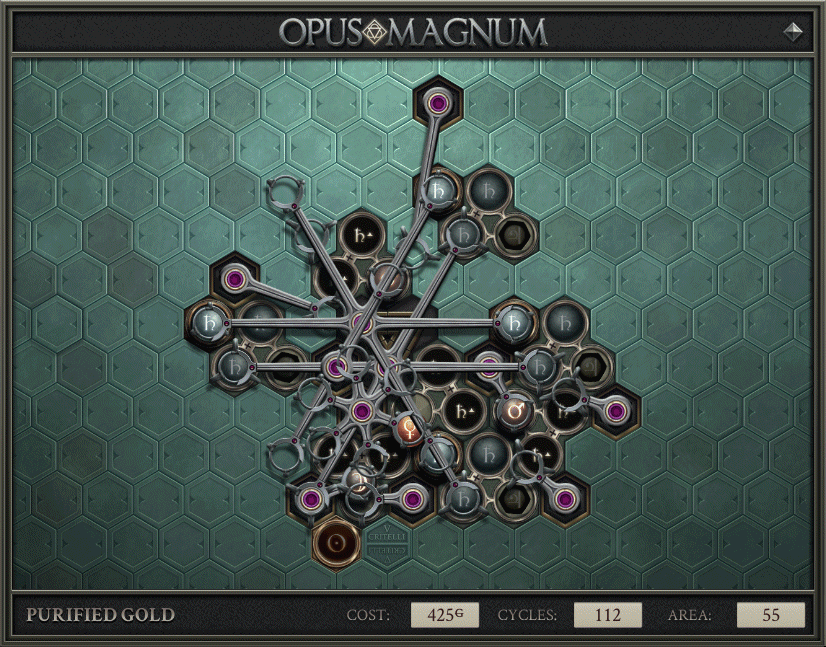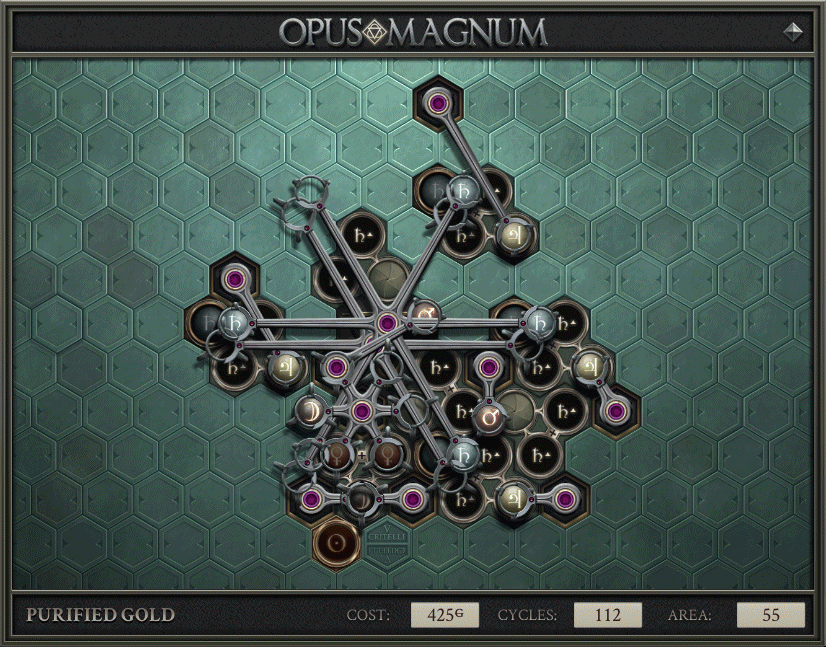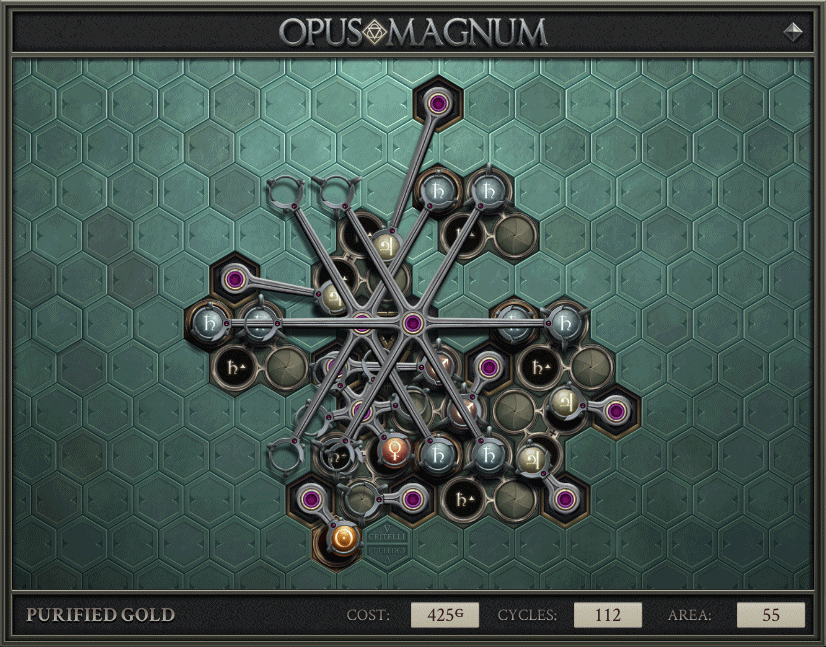
Probably the most interesting competition to come out of this leaderboard was on Purified Gold. The solution below attributed to SeerSkye is the “obvious” way to get minimum cycles. Devote an arm to every move, and a set of one or more purification glyphs to each stage. So long as you don’t mistime the grabs, it should come out to 112.

Things get more interesting if you ask how you could make this cheaper. Over the course of a couple weeks, submitters found better and better uses for multi-arms. Multi-arms are 50% more expensive, but you can replace several basic arms in the earlier solution by a single multi-arm. NoHatCoder was the first to post a minimum cycles solution at 425g. It uses quadruple-duty multi-arms, moving all 4 lead at once. They also used the same purifier for copper->silver and for silver->gold without losing any cycles, saving the cost of the glyph and reducing the number of arms needed to serve it.

Others then reduced the area while keeping the same cost and cycles, which is a tertiary improvement but an improvement nonetheless. The best solution 2 months later when Obyekt stopped wanting to own this leaderboard, was the following:

The next owner
While getting people to take on this secondary cost optimization was a major success, I didn’t like some of the choices Obyekt had made. Limiting the leaderboards to one specific way of playing the game, and only for some puzzles, meant that the leaderboards had always felt incomplete.
There would of course be an increased burden if anyone decided to support other metric combinations, and support all of the puzzles. But I wanted that to exist, and so I took over as the next leaderboard owner.
I drew on experience from a different Zachtronics game, TIS-100. Its leaderboard was organized into 4 categories for every puzzle, and operated on an honor system. My one major change was the following:
I would not attach names to any Opus Magnum records.
I cannot say that this was a uniformly good or uniformly bad decision, but it impacted the philosophy of record keeping and record hunting. Rather than competing with the community, which is how the in-game leaderboards always felt, the new leaderboard was a quest. Pick any puzzle and combination of metrics. Somewhere out there, is a perfect solution. Let’s try as a community to find it.
This avoided issues with attribution. Attribution meant maintaining a large list of contributors, like in the caption above. It was that or a situation where improving someone else’s solution allowed you to claim the record as your own. With neither of these burdens, the community became more openly collaborative. (For those who prefer the hidden competitive side of optimizing, there are still the tournaments).
Metrics per puzzle
The game scored your solution on cost, cycles, and area. However, in the then-newly-added production puzzles, instructions replaced area. Picking any ordering of the available 3 metrics as your primary, secondary, and tertiary metrics suggested 6 categories per puzzle.
I added one other secondary option. For a cycle optimized machine, you could also break ties using the product of cost and area. This was frequently a different solution, and Grimmy and I had already been competing against each other to optimize puzzles for this “Cycles, ties broken by Cost*Area” metric. We learned we were not the only ones, as panic posted his album of solutions optimized for the same. Extending this treatment by adding a product tiebreaker to cost and area primary, we found 9 metrics per puzzle.
In early 2018, based on popularity of the idea, we also added in “sum“. The canonical aggregate metric, it added the numbers together for cost, cycles, and area. In the unlikely event two solutions tied on sum, there would be separate entries for the one to have lowest in each metric. Such is the case for Reactive Cinnabar, where both of these solutions have the lowest known sum of 188, despite being very different from each other.


Improved automation
Shortly after we added sum, 12345ieee greatly improved the code for the bot. One thing he added was support for the pareto frontier.
What is the Pareto Frontier?
It may seem like sum is an arbitrary aggregate metric. Nobody said that one area and one cycle should compare as equal, especially since almost every puzzle has higher min cycles than min area. Additionally, Cost only can be a multiple of 5G, and G as a unit is arbitrary (fun trivia fact: G stands for Guilders). With all these factors at play, weighted sums, or products, seem just as valid. Thankfully, the Pareto Frontier is a construction that offers unlimited freedom for aggregate metrics.
To define the pareto frontier, begin with every possible solution to the puzzle. Call this collection the “pareto manifold”, where manifold is a math term referring to a collection of points in some well defined space. To get the frontier, eliminate any solution that fails a simple comparison to any other solution. That comparison goes as follows:
If the solutions are different, and one is better-or-equal on everything, that solution is unambiguously better. For example, the 425/112/55 purified gold is unambiguously better than the 425/112/76 before it. Losing this sort of comparison means a solution is not on the frontier.
However, if one solution is better in one way, and the other better in another, those solutions cannot be compared. For example, the 540/112/50 has lower area than the 425/112/55, while the latter has lower cost. Assuming there are no other solutions unambiguously better, both of them are on the frontier.
The pareto frontier thus holds every solution which cannot be improved on any axis without sacrificing something along another. With RP0’s guidance, the community attempted in early 2018 to collect enough solutions to Seal Solvent to compute a pareto frontier. The results are here, 33 scores which were unbeaten at the time.

Size concerns
Seal Solvent is not the simplest puzzle, but it is not that complex. For it to have 33 pareto scores from a small community effort, suggests that the task of record keeping may mean holding on to a lot of data. And that’s before we add any new metrics..
Mercifully, the leaderboard on the wiki never grew larger. Instead, the puzzle name itself became a link, which could allow a user to view the pareto frontier. In 2021, F43nd1r took over and integrated the bot with discord and his custom site. The site also served as a database full of submitted solution files. Now the link on the puzzle name in the wiki takes you to a page with a view like this:

This significant improvement in the architecture meant that we could, in theory, add support for even more metrics.
Bloat
So here’s everything we added!
Metrics that don’t require running the solution
The solution file format contains cost, cycles, area, and instructions as metadata. This is presumably because instructions is a primary metric in production puzzles, but it means that a bot can read off instructions for any puzzle with ease. (And area for a production puzzle, which is kind of funny).
A bot can determine whether or not a given solution uses overlapped parts, allowing players to submit overlap-cheated solutions without overwriting scores from legitimate solutions. Overlap gets a place of its own in the leaderboard.
The bot can differentiate between solutions that do or don’t use tracks, by looking for the “track” part among the parts list. For instruction optimization particularly, the decision to use or not use track wildly changes what is possible.
Metrics that do require running the solution
Since the very early days, throughput was a metric of interest. It’s like cycles, but without the rush to get low latency, and without the potential cheesiness of behaving differently after 6 outputs. The challenge with throughput, is understanding the steady state behavior of an arbitrary solution. With it being possible to build computers, calculate fast growing functions, and even make irrational numbers, it is definitely not an easy task.
With the advent of panic’s omsim, the bot could now determine a good estimate for throughput automatically. It would still fail for any solution that moved atoms arbitrarily far from the machinery and then used them again later, which is one of the hallmarks of the computational trickery above. But it could catch when this was happening and not give those solutions any more effort (and assign them no throughput score, similar to if the solution had simply crashed). This allowed for the creation of the “Rate” metric, which measures the average number of cycles between outputs of a well-behaved solution.
For clarity, a solution with optimal rate has optimal throughput, and vice-versa. Rate is just a way to pose the concept as a number you want to make smaller, which is consistent with all of the other metrics.
Geometric metrics
Also unlocked by omsim, are metrics having to do with the actual used area. Is the area increasing without bound? Is the area confined to a tube of some fixed height? Or a tube of some fixed width? These are all useful questions to ask that have more nuance than the simple area count, which is the number of used hexes when the “you win” screen pops up.


The 7D pareto frontier
The bot was now configured to score each solution along 7 axes.
- Cost (G)
- Cycles (C)
- Area (A)
- Instructions (I)
- Height (H)
- Width (W)
- Rate (R)
In addition, each solution had up to two flags, T for trackless, and O for overlap. T meant a solution could not be eliminated by solves that contain track. O meant that the solution would not eliminate legitimate solutions that didn’t overlap parts.
Grimmy’s quest
With this seeming like the status quo, Grimmy began to submit lots of solutions for the tutorial puzzle, Stabilized Water. Just how many solutions are on this 7D pareto frontier for a simple puzzle? You couldn’t beat a solution on just cost, cycles and area anymore. If the original solution had lower instructions, or a better height, or width or rate, it would remain.
Fortunately, the overlap portion of the pareto frontier is a single solution.

Using additional legitimate solutions, Grimmy was able to extend the pareto frontier to an absurd 786 points for Stabilized Water. They made a list of scores here, labeled by the required metrics for in order for the solution to be on the frontier.
For a salient example, here is a solution which requires every single metric before it is pareto optimal:

This solution beats every other solution on at least some aspect of the score (when accounting for tracklessness, cost, cycles, area, instructions, height, width, and rate). But if you ignore any one of those metrics, a solution exists that is better-or-tied in everything else, and would thus eliminate this one. Click each of the links above to see that solution.
Solutions of interest
While every solution on the pareto frontier has merit, some answer a simpler question than others. If you care about throughput, then cost, then instructions, then area, you would want to know what the RGIA solution was for stabilized water. And that would be the following:

With a large database and a good bot, you can find the common metric combinations easily. By keeping the pareto frontier, the community made the task of identifying the more conventional Opus Magnum records very easy to automate.
But, when you download this solution, you will find that it has a dark secret..

RA abuse and friends
The solution above saves 3 area by waiting until the “you win” screen comes up before starting its lower machinery. The three area on the right do not contribute to the 20 area in the score, despite the atoms passing over them in the gif.
The game treats these two metrics, cycles and area, as absolute truths about the solution. Unfortunately, that is a lie. They are specific properties of the solution when measured the moment it has completed 6 outputs. They do not necessarily hold indefinitely, which puts them at odds with the rate metric.
For a related example of RC abuse, here is a different solution, to Quintessential Medium in the journal.

There’s a whole mess of stuff in the middle, which allowed the solution to hit 24 cycles. After those cycles ended, the rest of the machinery began, which outputs with perfect rate but high latency. It’s a perverse and brilliant amalgamation of the (not full throughput) cycles record and an old throughput solve of mine, allowing it to have both properties at once.
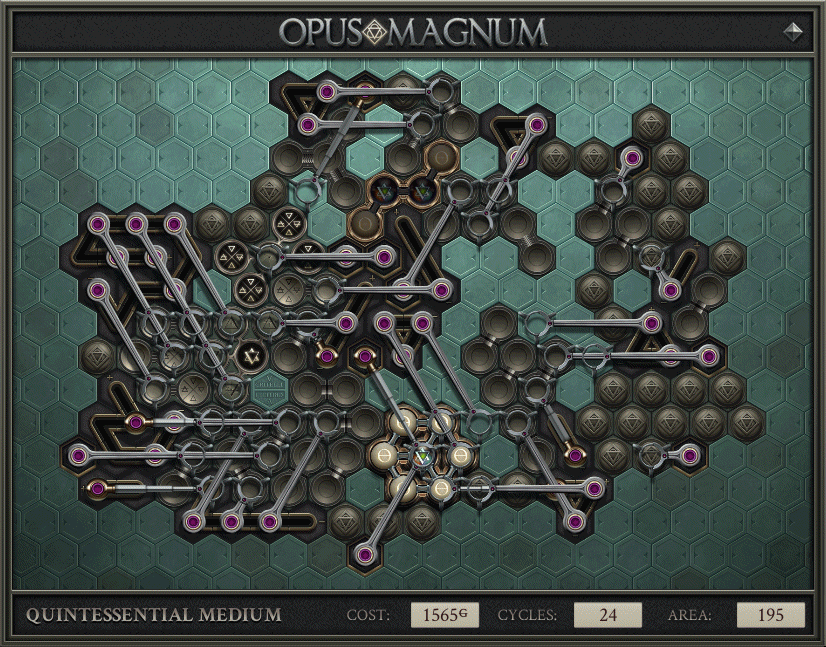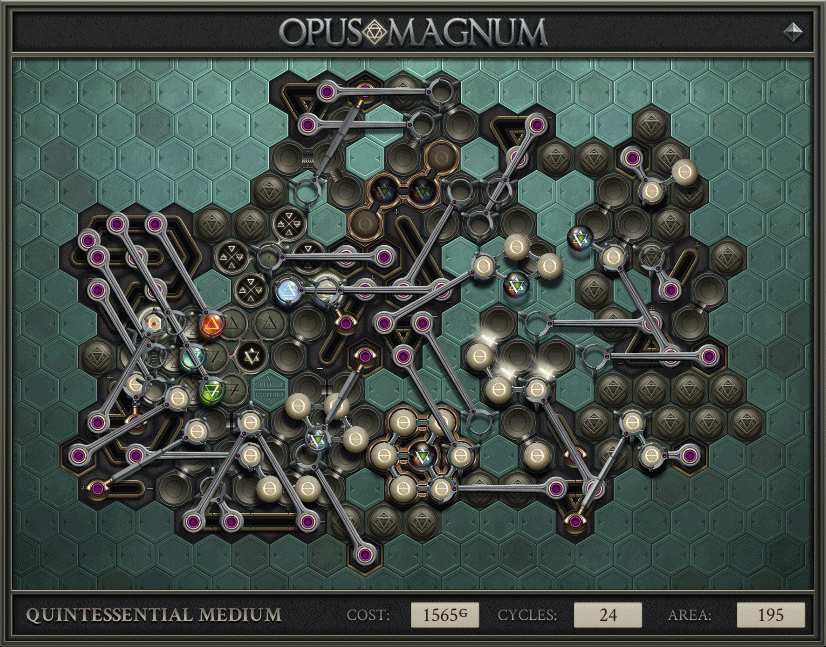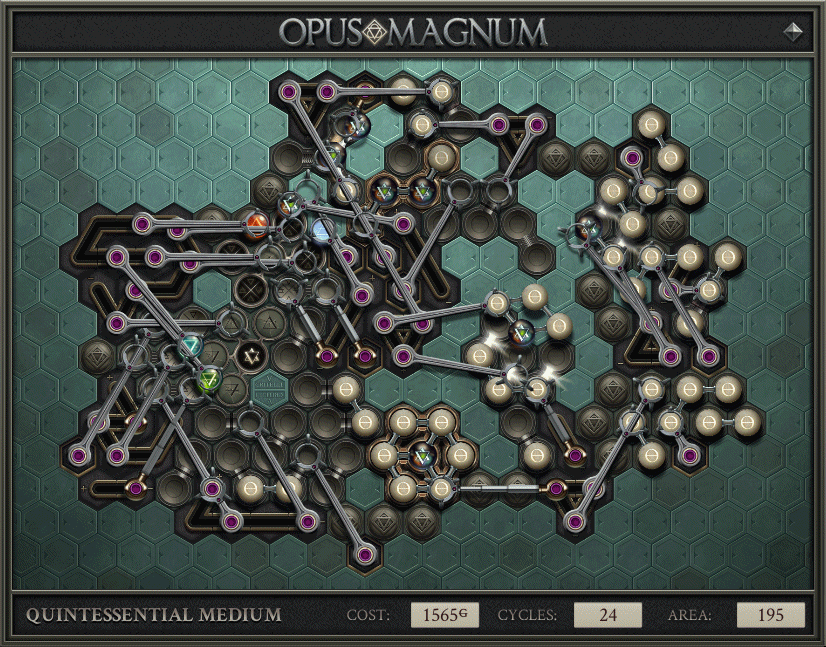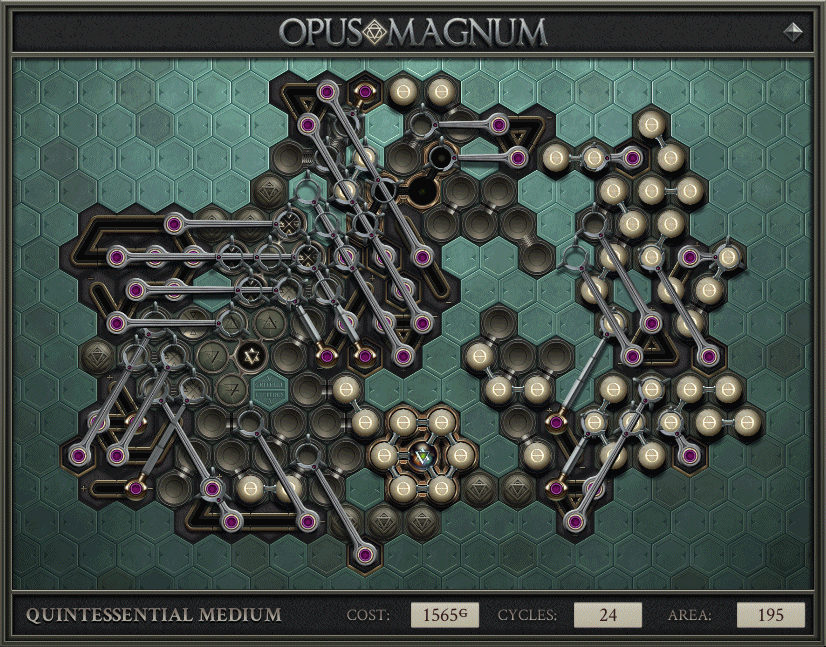{kind=link}
Clearly, measuring solutions both at the “you win” screen, and at infinity, encourages some rather bad behavior in the interest of gaming the system. Madmaster himself even described the above endeavor as “something dumb”.

The Pareto Manifold Split of 2023
12345ieee, back again to improve our infrastructure, began 2023 by promising his efforts to a project. His words follow:
Metrics (like area, cycles, height, etc…) aren’t fixed during runtime, but they evolve based on time (aka cycles in OM). To make these metrics a number, one chooses a measure point at which the metrics are measured and the level is won. For OM this is usually at 6 outputs (exceptions apply), so the normal metrics are measured at the cycle the 6th output is dropped. We call this measure point
@6, so the usual area metric can be represented byA@6and so on…There is another measure point that all zachlikes have, which is
@0, used for metrics that don’t change with time, like cost or tracklessness, so the usual cost metric isG@0.Now the community here wanted more, so we started measuring Rate without developing a formal theory first, so we didn’t realize we actually introduced a new measure point, that we call
@INF.
@INFis formally the limit of the metric as cycles go to infinity. It’s possible to define more meaningful metrics at@INF, like area or width.Now that the game has 3 measure point though, there is an issue.
@0is compatible with any other measure point, as it’s used for constant metrics, but any two other measure points are NOT compatible. And by compatible I mean that a pareto frontier that has metrics from 2 different measure points will generate monsters.Consider the poster child of the issue, the
(R@INF,A@6)frontier. The optimal way here is not to make a “fast but small” solution, like it would be in(RA)@INF, but it is to get theA@6record, have it do 6 outputs, then start the optimal rate machinery after the 6th product is dropped. This is not a RA-specific issue, but it’s an inherent property of using multiple measure points in the same pareto manifold.Therefore it’s been decided to do what is called the pareto manifold split, which means separating the metrics of a solution in 2 distinct subscores that go into 2 different pareto manifolds altogether.
12345ieee
The pros
On the surface, this is a great proposal with no complications. Solutions like this, which are notable for their infinite behavior (outputting at the maximum rate) compare against their peers on the @INF manifold.

@INF manifold, the area would be deservingly labeled as infinite. The 12443 area computed here is hardly relevant.While solutions like this, which are notable for their behavior prior to the win screen only (an area solve that balances waste), compare against their peers on the @6 manifold.
Implementation
When you submit a solution, the bot will first check for tracks, check for overlap, compute cost, and compute instructions. Then it will run the solution to 6 outputs to check cycles, current area, height and width. Save the results in the @6 manifold, then compare it only against other solutions in that manifold.
Next, attempt to find the steady state. If the solution doesn’t have a steady state (due to crashing, desyncing, or computational trickery) give up and don’t assign the solution any @INF point. Compute rate. Recompute area, height, and width, if any of them is consistently increasing upon returning to steady state, mark that metric as infinite for the @INF manifold. Any solution with valid results in the @INF manifold gets compared against other solutions in that manifold, to determine a totally separate frontier.
This would mean that certain combinations of records go away completely, while others are made far more clean. The RC record for quintessential medium would not exist on either frontier, because the thing that set it apart in one is only defined in the other. The RGIA record for stabilized water would be 23 area and not 20, because the area would be measured in the @INF manifold (due to the presence of R).
There was one straggling question.
Nerds quibbling over aesthetics
Gifs look much better when they loop. Every solution has an associated gif, which, thanks to Syx’s project, is now automatically generated from the solution file. As we have seen, some solutions achieve very good @6 scores by programming all the way up until the “you win” screen, defying the game’s natural loop.
When combining these facts, both of the following are currently valid gifs of records for litharge separation CGA.


For clarity on what “both of them are the record” means – asking the bot for the record will just bring up whichever one was submitted most recently. But when viewing the pareto visualizer on F43nd1r’s website, the dot associated with the CGA point would have two solutions, and you would be able to see them both, since they contain a tradeoff on an unspecified axis.
After the split, the second will unambiguously beat the first. The only thing the first had going for it was that it had a rate when the second didn’t. Since it’s a cycles record, post-split it would only exist on the @6 manifold, where rate is no longer in the equation. Instead of the status quo, where both of them are the CGA record, now the latter is the one true CGA record.
But the first one went to the effort to loop. I don’t like a situation where that very effort eliminates it from the frontier, in a game about looping machines.
Proposals
12345ieee invited us into a discord thread, with 24 hours to come up with a clear picture of what we wanted. I always appreciate developers who choose to get some community input instead of just unilaterally deciding how their tools work.
Proposals were:
- Suck it up, the second solution truly is better and deserves to be what people see when they ask for the record.
- Allow someone to submit the “wrong” gif, so that the record in the database is the latter but the gif for it is the former.
- Define “I2”, an instructions metric that can be different from the instruction count in the solution file. Any instruction which has never executed by the time the “you win” screen comes up, is not counted for I2. Folks could do as they please to allow this type of solution to reset back to its initial state, free of consequence.
- Create a “Looping” flag to place on the same footing as Tracklessness and Overlap. A looping solution would not be eliminated by a non-looping solution, even if its stats were worse on all other axes.
Discussion
I’ve ordered them from my least favorite to my most favorite, but the discussion was very active. There were merits and drawbacks for each approach. I2 in particular had a lot of nuance to discuss. However, the existence of production puzzles, where the gif displays instructions as a first class metric, means it set a poor precedent. If we were allowing solutions to have extra instructions after completion, the gif would lie. Why then, would we not give cost the same treatment? Adding a bonder may allow area solutions with waste to loop, which wouldn’t loop without it. Since the bonder is inactive until after the “you win” screen, should we allow it to count as free? Would its area also not count?
The drawback of the looping flag was principle only. The @6 manifold shouldn’t care whether or not a solution loops. The whole point of the @6 manifold was to ignore anything that gets measured at infinity. But, it was the inelegant solution that made the most people happy. Gif enjoyers could still see their looping solutions on the pareto frontier, regardless of the loop-less solutions that took fewer instructions to set the same score.
The looping cycles enjoyers thank you 12345ieee, for letting our creations survive the purge.

Closing remarks
I’m sure there will be more wrinkles in this story.
Setting area to infinity in the @INF manifold where applicable is a good way to challenge waste chains, but it also means that polymer outputs, destined to grow without bound, can never do better. Maybe a more nuanced measurement is possible with omsim.
Rate and instructions still coexist in the @INF manifold, meaning one can often find an infinite family on the pareto frontier. That’s a can of worms I didn’t touch here.
Additionally, people are still deciding if we are measuring the right set of metrics. Do we think width actually matters? Do we want to add new metrics around limiting glyph use?
I do think that there will always be cool solutions that don’t fit the mold. Those solutions aren’t going to be retrievable using this nice API that the tool owners have put together. But, they can be posted on discord, or reddit, or anywhere that solutions can be shared. When you pick the venue, you can choose whatever restrictions you please.
The game is open ended. Play with it how you will. Maybe you can compel our tool makers into validating your playstyle with a new axis of measurement. Just expect some of the nerds here to try their hardest to formalize it first.